
The Proximal Origin of LLM Response Information
Introducing Seeds of Truth, an AI for public benefit.


The censorship-industrial complex that rose to power during the pandemic uses every means at its disposal to control what information we're allowed to see, what we're allowed talk about, and how we're allowed to talk about it. As WantToKnow.info's news editor throughout this period, I've been acutely aware of the escalating manipulation of search results and social media feeds. Now, more and more people are forgoing traditional search altogether and going directly to AI to ask their questions. Have you ever asked an AI a question about a controversial topic and received an answer that felt censored?
At the beginning of this year, a small team formed to begin exploring the possibility of creating an AI that could provide unfiltered answers to questions about high level corruption, suppressed medicine, and all of the other controversial topics WantToKnow focuses on. This exploration has since blossomed into a serious public benefit project called Seeds of Truth, sponsored by Public Education and Empowerment Resource Service (PEERS), WantToKnow's parent organization.
This specialized AI is being developed by two experienced engineers and myself. We're using an interesting combination of well-understood techniques to modify a pre-trained large language model (LLM) that will provide both good answers to questions on suppressed topics and references for the probable sources of the information contained in those answers. Our initial results are promising. Something very cool is emerging. Here's a glimpse into the technical underpinnings of Seeds of Truth.
Vector Index Approximation
The information used to train the current generation of accessible LLMs is encoded into those models in a way that makes it impossible to determine which specific pieces of training data are incorporated into a given response to a user's question. So there's no way to know for certain where exactly an LLM obtained the information it uses to answer a question. While LLMs sometimes provide references, many of these turn out to be incorrect or nonexistent. These things limit the utility of LLMs for certain kinds of research.
Although determining the origin of an LLM's answer to a question may be impossible, the answer's proximal origin can be identified by vector index approximation (VIA). This method identifies places in a dataset that contain information that's most similar to the information contained in an inference response. The origins of these dataset entries are reported to the user along with the LLM's response, providing the user with the most likely sources of the information contained in the response.
This system relies on standardizing and indexing the dataset used to train an LLM. In the idealized case, vector embeddings would be computed for every piece of text data used to train an LLM from the ground up, and every chat completion response could be matched with the training data from which it originated. The VIA method was applied to a partial indexing of text data used for training a DeepSeek LLM, with satisfactory results.
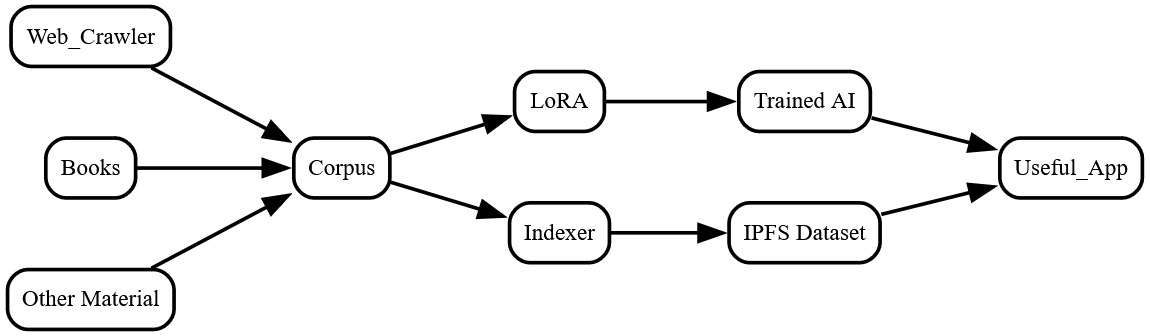
Seeds of Truth
Initial calibration and testing of the model were conducted with the WantToKnow.info news article summary database, containing about 14k entries. Training DeepSeek on this data produced inference responses that surfaced relevant information with satisfactory accuracy. Using these responses to search the indexed dataset produced specific entries that closely matched the response information, making it possible to review these entries for use as cited information sources.
Training was completed using LoRA, which stands for Low-Rank Adaptation. This is a technique used to efficiently fine-tune large pre-trained machine learning models. According to Hugging Face, LoRA is "a popular and lightweight training technique that significantly reduces the number of trainable parameters. It works by inserting a smaller number of new weights into the model and only these are trained. This makes training with LoRA much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), which are easier to store and share."
Embedding was completed using both TF-IDF (term frequency and inverse document frequency) and bge-base-en-v1.5. BGE stands for BAAI General Embedding, a series of embeddings models developed and published by Beijing Academy of Artificial Intelligence (BAAI). TF-IDF is good for keyword search, while BGE is better for semantic search. Combining the two could maximize the accuracy of dataset searches, though TF-IDF alone was used for initial testing of the VIA.
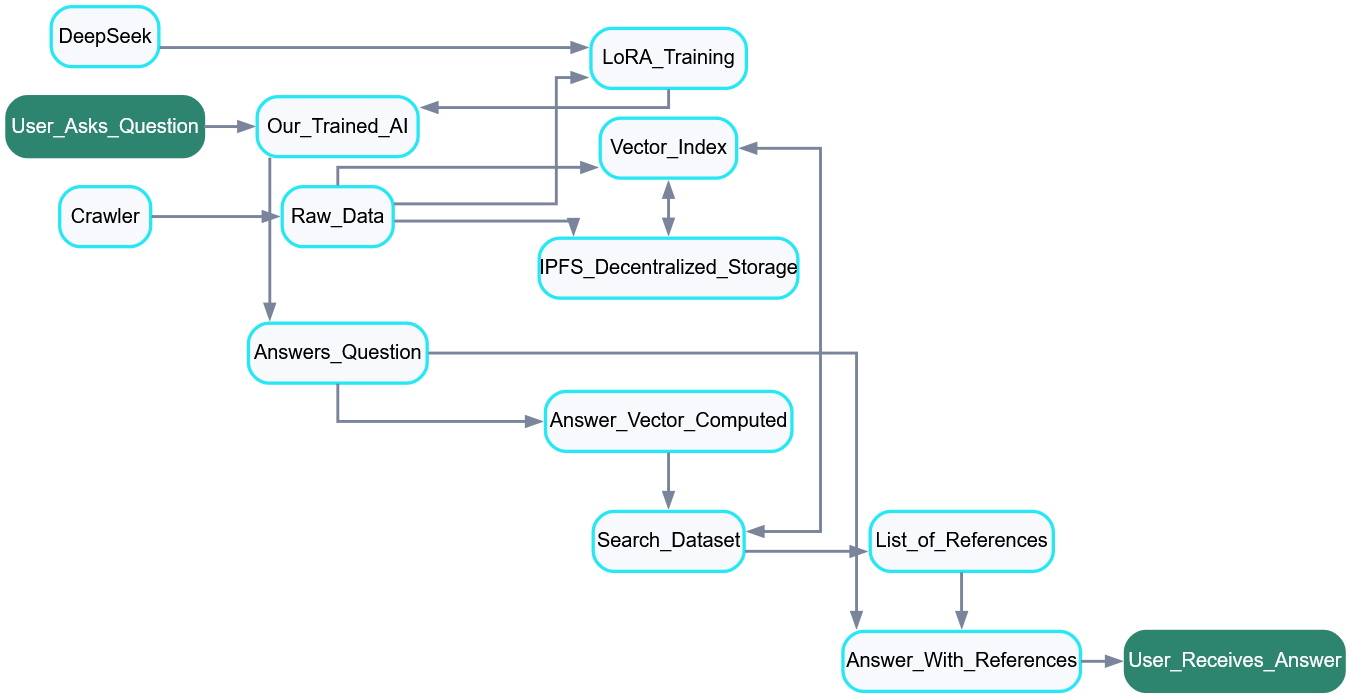
The AI and the Dataset
The Seeds of Truth AI will initially be built on a 32 billion parameter DeepSeek LLM. Preprocessed training data from a web crawler, contributing publishers, and other sources will be used to train the LLM. This data will also be divided into small standardized chunks of text, indexed according to its vectors, and stored on IPFS. The number of text chunks will be high, so vector index sharding will be employed.

In initial tests, index sharding was done using K-means clustering to identify n centroids in the dataset's total vector space. Each shard indexed only the closest vectors, and an index of the centroids routed queries to their closest 1-3 clusters. The first test produced 30 clusters with between 47 and 999 items per cluster. A search routed to just 3 clusters produced results of high relevance. It may be possible to improve this efficiency by adjusting clustering parameters. You can see how it all works in this Jupyter notebook.
The total Seeds of Truth dataset will contain every piece of training data along with the webpage or publisher it came from. This will be stored on IPFS, as will the dataset indexes, vocabulary, and manifests. The indexes/manifests may also be registered on the Hive blockchain. The result will be a robust decentralized dataset that's easy to reference, and easy for AIs and apps to talk to.
One app that's envisioned would allow users to rate, comment on, and share information sources with each other. It should also be possible to build a retrieval-augmented generation (RAG) system on the dataset without too much trouble or incorporate the LLM into a mixture of experts system. Wherever Seeds of Truth goes, I'm sure it'll be awesome, and I'm loving being a part of it.
For more of my writing, check out my science fiction novels.